io_uring 机制学习
Table of Contents
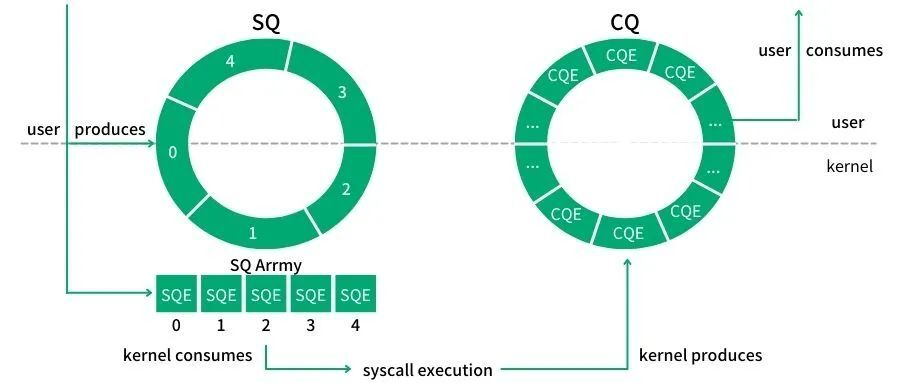
SQ: Submission Queue,提交队列,用于存储将对其执行操作的数据。 CQ: Completion Queue,完成队列,用于存储任务完成的结果。 SQE: Submission Queue Entry,提交队列中的一项 CQE: Completion Queue Entry,完成队列中的一项
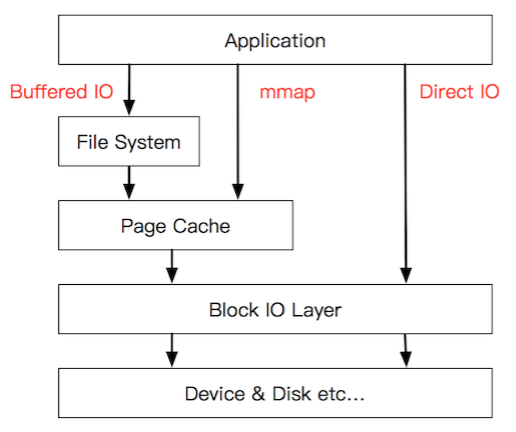
buffered I/O vs direct I/O⌗
- 缓存 I/O 中,调用 read 时,会写读取内核地址空间的页缓存,如果页缓存有数据就直接把这个数据返回给应用程序,否则就首先从磁盘读取数据到页缓存,然后再从页缓存拷贝到应用程序的地址空间。调用 write 时,会先将应用程序的地址空间拷贝到内核地址空间的页缓存,然后再写入磁盘。根据 Linux 的延迟写机制,当数据写到操作系统内核空间的页缓存,write 就完成了,内核会定期将页缓存的数据刷新到磁盘上。这样,缓存 I/O 就基于页缓存减少了读写磁盘的次数,从而提高了效率。读数据会存在两次拷贝:从磁盘拷贝到页缓存,从页缓存拷贝到用户缓冲区。写数据会存在两次拷贝,从用户缓冲区拷贝到页缓存,从页缓存拷贝到磁盘。
- 直接 I/O 则绕过页缓存,直接与磁盘直接进行数据传输,不会经过页缓存。
libaio 的不足⌗
- 不支持缓存 I/O,只支持直接 I/O,在使用 async IO 时,必须使用 O_DIRECT
- API 设计存在问题,每次 I/O 请求需要两次系统调用:提交请求+等待请求完成
- 其中提交请求需要拷贝 72 字节数据
- 等待请求完成需要拷贝 32 字节数据
io_uring 的优势⌗
io_uring 设计了一对共享的 ring buffer 用于应用和内核之间的通信,从而避免了在提交和完成任务时的内存拷贝,避免了在提交和完成任务时的系统调用过程,队列采取了无锁的访问模式,通过内存屏障减少了竞争。
初始化⌗
struct io_uring_params {
__u32 sq_entries;
__u32 cq_entries;
__u32 flags;
__u32 sq_thread_cpu;
__u32 sq_thread_idle;
__u32 features;
__u32 wq_fd;
__u32 resv[3];
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};
struct io_sqring_offsets {
__u32 head;
__u32 tail;
__u32 ring_mask;
__u32 ring_entries;
__u32 flags;
__u32 dropped;
__u32 array;
__u32 resv1;
__u64 resv2;
};
struct io_cqring_offsets {
__u32 head;
__u32 tail;
__u32 ring_mask;
__u32 ring_entries;
__u32 overflow;
__u32 cqes;
__u32 flags;
__u32 resv1;
__u64 resv2;
};
long io_uring_setup(u32 entries, struct io_uring_params __user *params)
该函数返回一个文件描述符,在该文件描述符中存储了 io_uring 支持的功能。 同时,在 params 中存储了 SQ 和 CQ 的 offset。
- sq_entries: 返回内核分配的 sq entries 数量
- cq_entries: 返回内核分配的 cq entries 数量
- flags: 用户可以设置标志位,改变 io_uring 的执行方式
- sq_off & cq_off: 告知用户侧如何使用 sqring 和 cqring
The flags, sq_thread_cpu, and sq_thread_idle fields are used to configure the iouring instance. _flags is a bit mask of 0 or more of the following values ORed together:
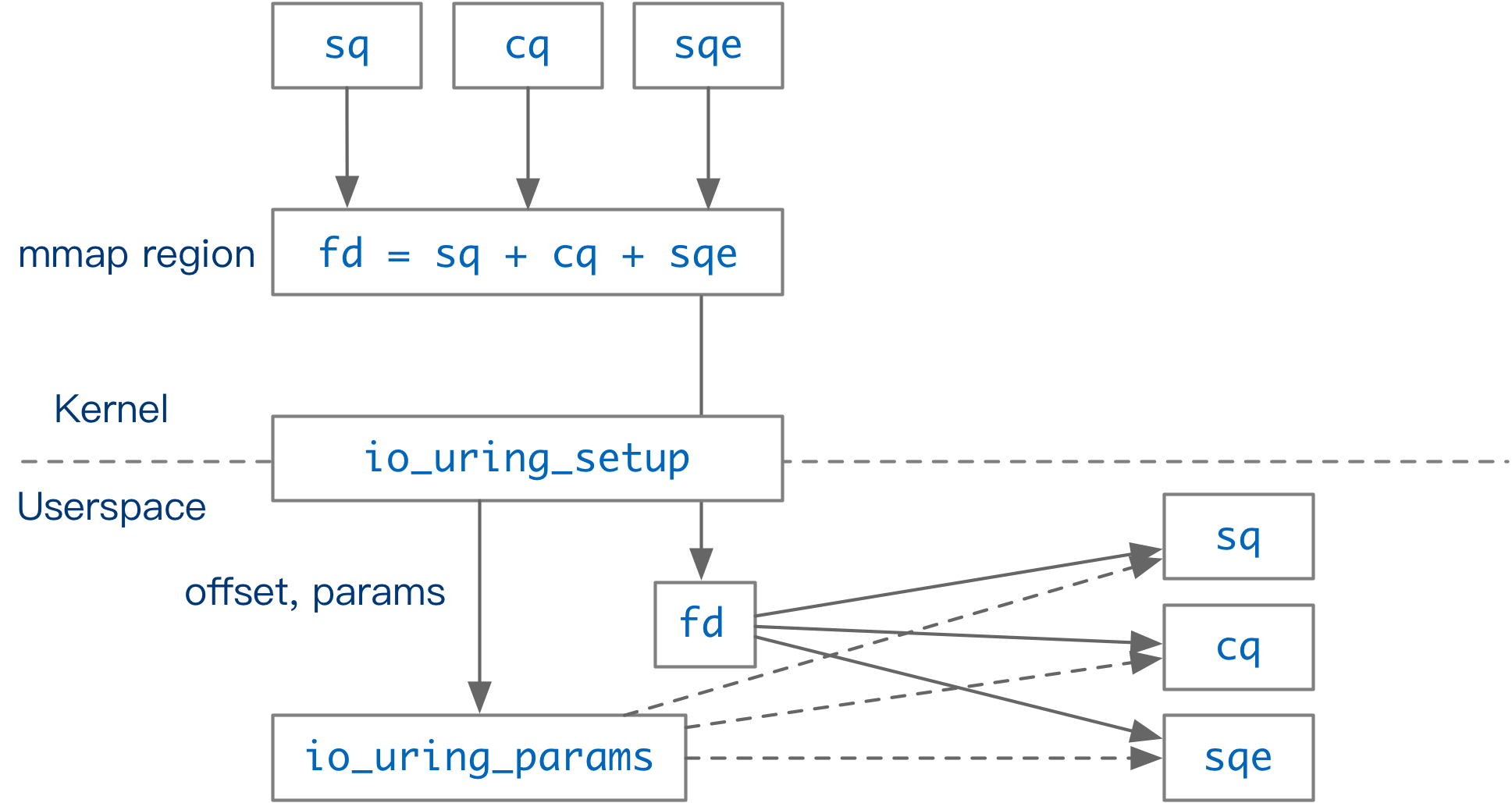
SQE 相关数据存储在 io_uring_sqe 结构体中,CQE 相关数据存储在 io_uring_cqe 结构体中,SQRing Offset 数据存储在 io_sqring_offsets 结构体中,CQRing Offset 数据存储在 io_cqring_offsets 结构体中。
默认,SQE 大小为 64 字节,CQE 大小为 16 字节。
int io_uring_register(unsigned int fd, unsigned int opcode,
void *arg, unsigned int nr_args);
任务⌗
io_uring 可以处理一系列与 I/O 相关的请求。
- 文件相关:read, write, open, fsync, fallocate, fadvise, close
- 网络相关:connect, accept, send, recv, epoll_ctl
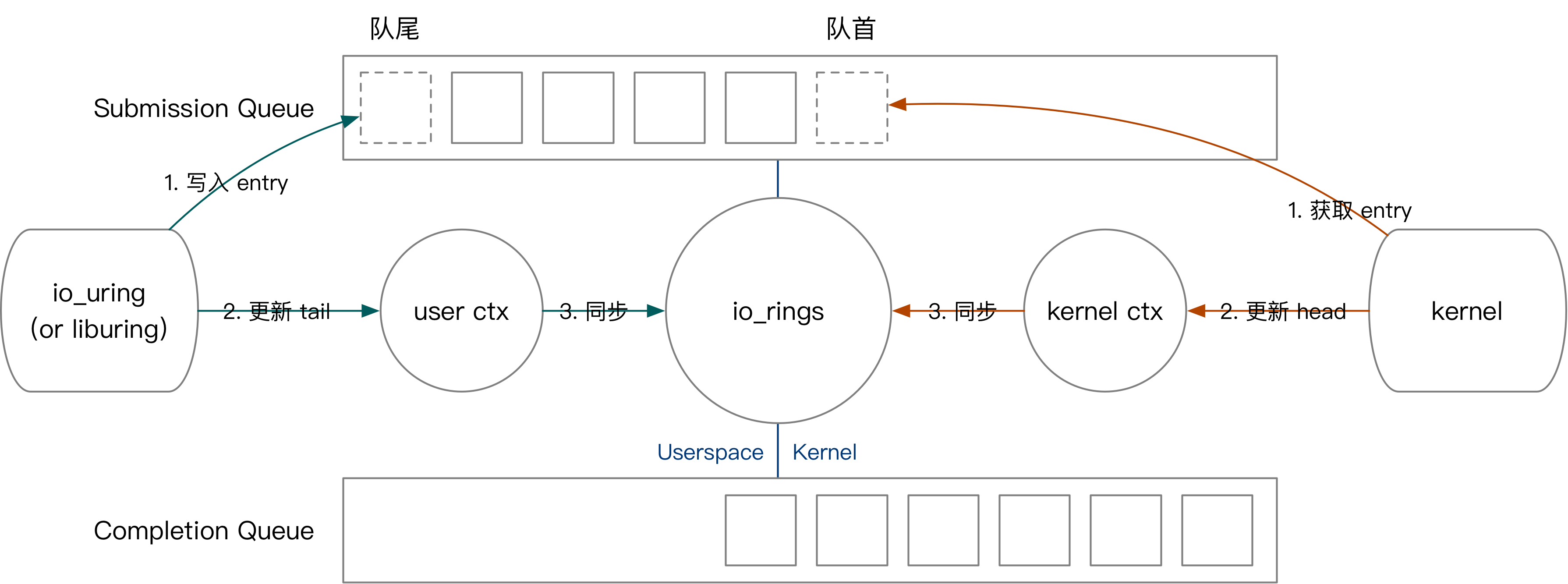
用户侧负责 SQE 的创建,内核侧负责 SQE 的处理。 内核侧负责 CQE 的创建,用户侧负责 CQE 的处理。
在创建 io_uring 时,如果 IORING_SETUP_IOPOLL 被启用,那么 io_uring 将会使用 polling 模式执行所有操作;如果 IORING_SETUP_SQPOLL 被启用,那么 io_uring 将会在内核创建一个线程,在该线程中执行用户提交的任务。
design goals⌗
- No memory copies for either submissions or completion events
编程方式⌗
- 使用 io_uring_setup 和 mmap 设置共享 buffer,在内核态和用户态共享 SQ 和 CQ。在用户态构造 SQE 插入到 SQ 以提交 I/O 请求,在内核态将 I/O 请求结果添加到 CQ
- 对于每个 I/O 请求,需要构造 SQE 描述该 I/O 请求,然后将它添加到 SQ 的末尾
- 添加 SQE 之后,需要调用 io_uring_enter 告诉内核处理该 I/O 请求
- 内核处理完成该 I/O 请求后,会构造 CQE 添加到 CQ 的末尾,用户态获取 CQE 之后,通过检查 res 的值,可以得到 I/O 请求的结果
- You add SQEs to the tail of the SQ. The kernel reads SQEs off the head of the queue.
- The kernel adds CQEs to the tail of the CQ. You read CQEs off the head of the queue.
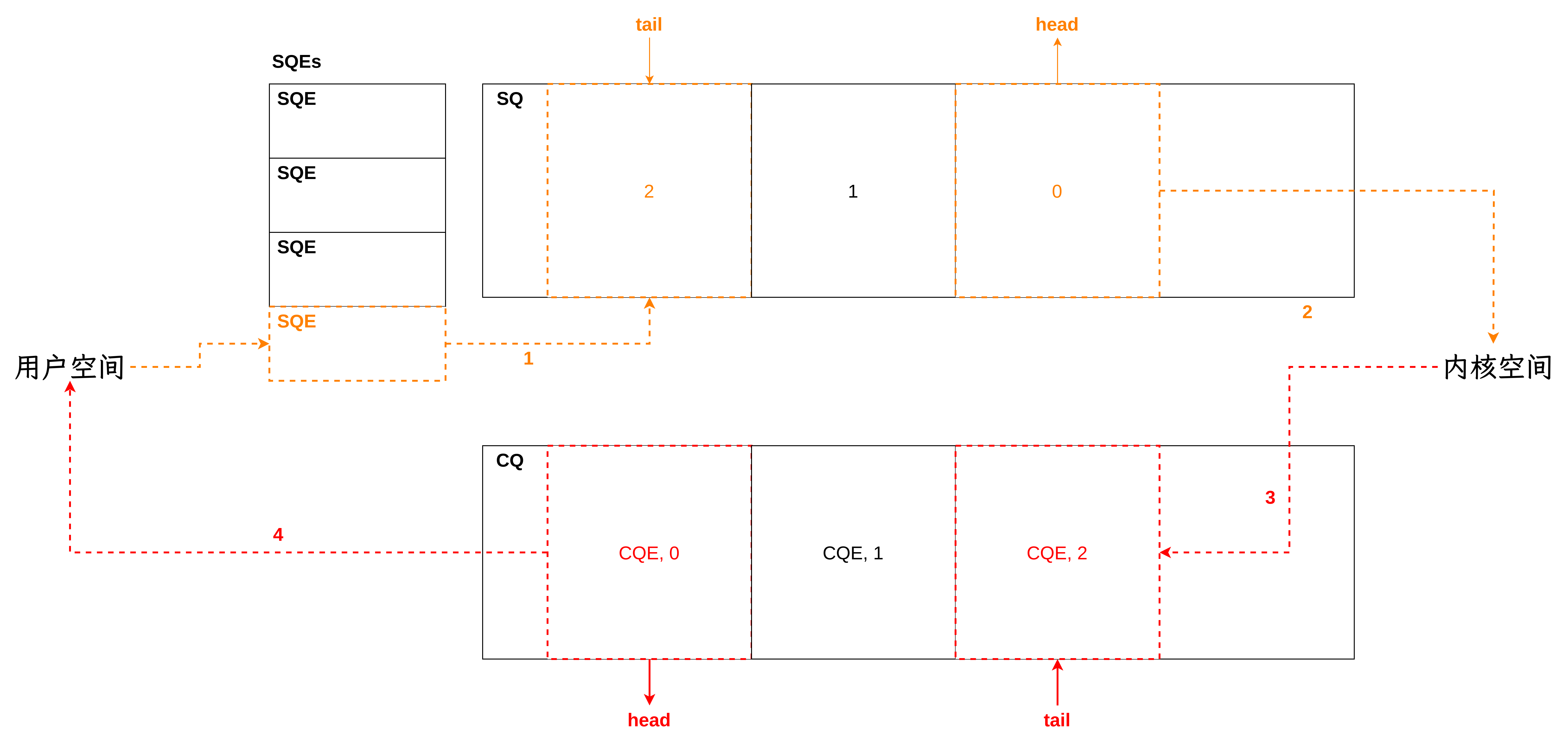
io_uring 利用在内核态和用户态共享的 SQ 和 CQ 达到了零拷贝。
如何更高效?⌗
使用 IO_POLL,不依赖硬件中断而是轮询处理完成事件,用户需要在用户态轮询 CQ,判断 CQE 状态,进行相应的处理
使用 SQ_POLL,可以完全不调用 io_uring_enter(相当于完全没有系统调用)
liburing & echo server⌗
io_uring_queue_init_params⌗
- io_uring_setup
- mmap(SQ, CQ, SQEs)
IORING_FEAT_FAST_POLL⌗
Available since kernel 5.7.
// check if IORING_FEAT_FAST_POLL is supported
// 在快速轮询模式下,io_uring 机制会使用 epoll 机制来监视文件描述符上的事件,
// 而不是使用传统的I/O复用技术,如select或poll。
// 这可以减少系统调用的次数,从而提高I/O操作的性能。
// 启用IORING_FEAT_FAST_POLL特性标志后,io_uring机制会使用快速轮询模式来
// 处理文件描述符上的事件。高版本下这是自动设置的。
if (!(params.features & IORING_FEAT_FAST_POLL)) {
printf("IORING_FEAT_FAST_POLL not available in the kernel, quiting...\n");
exit(0);
}
io_uring_get_probe_ring⌗
io_uring_get_sqe & io_uring_prep_provide_buffers⌗
准备好 buffers 存储读和写数据,初始化 sqe。